Novel Augmented Reality (AR) applications often utilize state-of-the-art machine learning methods. In the recent viral AR Cut & Paste demo video on Twitter, its author Cyril Diagne adapted BASNet, a neural network proposed by Qin et al., to remove backgrounds from photos taken by his phone. This type of task is called salient object detection (SOD), and many different neural networks have been proposed to perform this task. Implemented in PyTorch, U2-Net is a new SOD neural network architecture proposed by the authors of BASNet, and it is able to achieve better performances with a smaller model size. To better understand how it works fundamentally, I teamed up with two software engineers to reimplement and retrain the U2-Net from scratch in TensorFlow.
My role in this project is to train the model and experiment with its hyperparameters to see how they affect the model’s performance. The model was trained for a total of 70000 epochs with a batch size of 9 on two different datasets - HKU-IS and DUTS-TR. The model was able to produce results similar to those of the original implementation. The feature video above shows how the model was learning to perform better during the training process.
Machine Learning Researcher & Engineer
Nov - Dec 2020
Jiaju Ma, Carrie Zhuang, Shuyan Wang
TensorFlow, OpenCV, Python
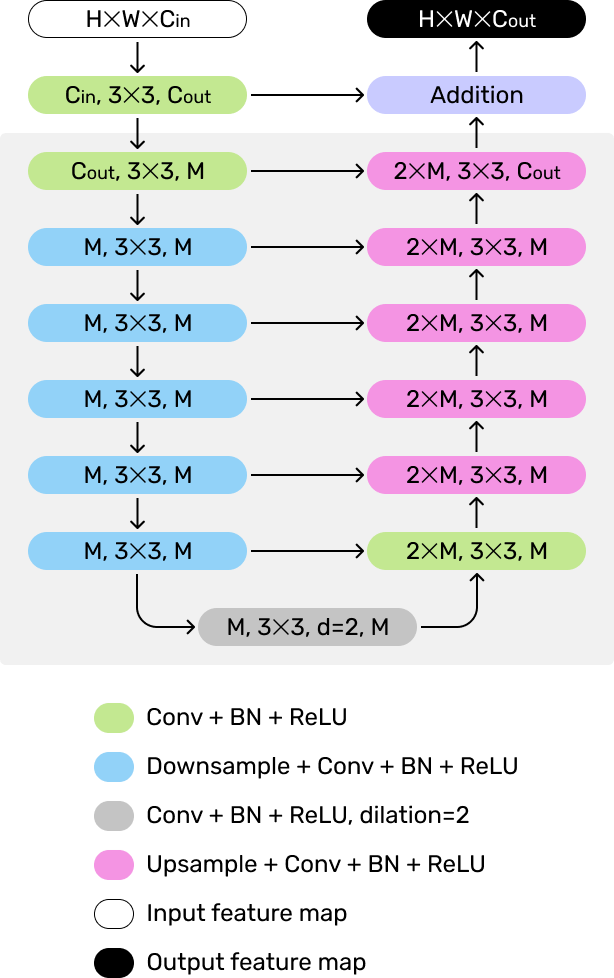
As pointed out by Qin et al. in the U2-Net paper, many SOD architectures rely on reusing image features extracted by pre-trained large neural networks such as AlexNet, VGG, and ResNet. On a high level, architectures built in this manner are often overly complicated and need to sacrifice image resolutions in order to run in a computationally efficient way. The architecture of the U2-Net is able to address these issues through its nested U-structure and novel ReSidual U-blocks (RSU). Please refer to the Methodology section for more details.
The constituent unit of the U2-Net is the ReSidual U-block (RSU), a U-shaped Encoder-Decoder structure consisting of symmetric convolutional layers. Inspired by U-Net, RSU allows image features of various scales to be extracted through sequential downsampling on the encoder side. Features extracted at each level are preserved and directly added to the corresponding layers on the decoder side during the upsampling process. The authors stated that this structure can retain fine details that might be lost due to large-scale upsampling.
The outer U-Net structure consisting of RSU blocks creates a nested U-structure, giving this model the name of U2. As stated in the paper, connecting multiple U-Net-like structures to create different architectures has been explored before, but they usually stack each unit in a linear manner and can be thus categorized as “U × n-Net”. The main flaw of this type of approach is that both the computational and memory costs are multiplied by n. In the U2-Net, RSUs are stacked in a manner similar to how each of them is constructed - a U-shape Encoder-Decoder. There are 6 units in the encoder and 5 in the decoder. Each level produces a saliency map, which is combined together with the other maps to form the final output. This nested architecture can extract and aggregate features at different levels and scales more efficiently.

In our reimplementation, we built the same architecture using TensorFlow in Python, and trained our model from scratch on a NVIDIA Tesla K80 GPU. Most of the hyperparameters used are in line with the original paper, but we had to reduce the batch size from 12 to 9 due to smaller GPU memory size. We firstly trained our model on the HKU-IS dataset for 30000 epochs, and the loss decreased from 6.99 to around 0.18. As a way to add data augmentation, we further trained our model for 40000 epochs on the DUTS-TR dataset, which is used in the original implementation. The loss initially jumped to around 1.22 but converged again at around 0.18. Every 100 epochs took about 4 minutes to train, so in total our model was trained for around 48 hours.
To qualitatively evaluate our model, we chose the first 10 images from the DUTS-TE dataset and ran them through both our model and the original model trained in the paper. You can find the side-by-side comparison shown below. The first two columns are the original input images and their ground truth saliency maps. The third and fourth columns are the maps created by our model and the images with the maps applied. The final two columns are output by the original model.
The original model was trained on a more powerful GPU (NVIDIA GTX 1080ti) for 120 hours. Due to resource constraints, we could not train our model in the exact same way, but our model was able to achieve similar results qualitatively overall. Outputs in the fourth and tenth rows are suboptimal, as parts of the human bodies are excluded. However, our model was able to capture finer details and perform closer to the ground truth than the original model in some cases, like in row 5 (nozzle), 7 (beak), and 9 (tail). We believe that the mixture of datasets used for training partially mitigated negative effects of shorter training time.
